Big Little Indian Conversion
Some time ago I received a query about how to convert from Big Indian to Little Indian or vice versa, since what we are going to propose is simply to invert the order of the Bytes.
First, a brief description of Big and Little Indian, their difference lies in how data is ordered in memory, "Little" The least significant Byte is stored at the lowest address and the most significant Byte at the highest, on the other hand "Big" The most significant Byte is stored at the lowest address and the least significant Byte at the highest address.
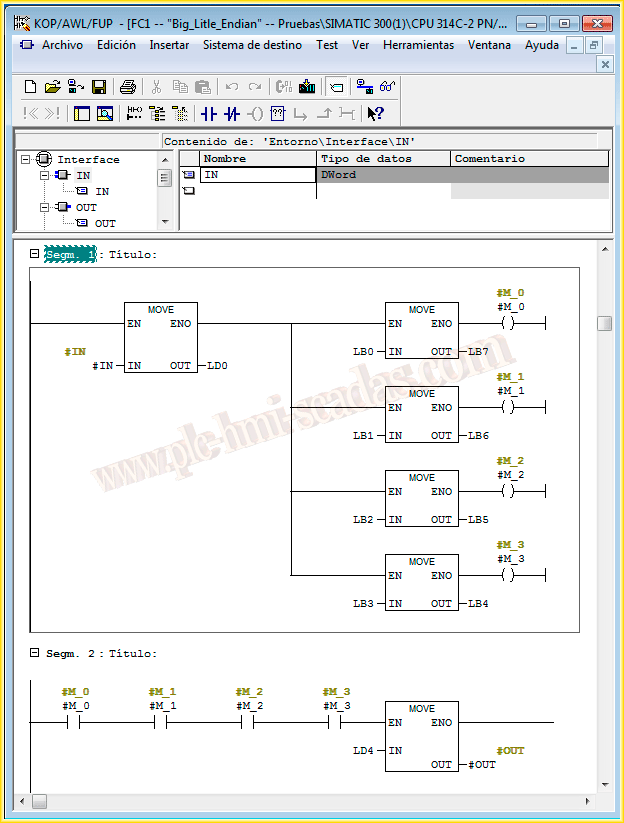
For this, we are going to create a FC Function, where we will pass a DWORD as input parameters and as output we will obtain another DWORD with the Bytes inverted.
With the following image, I don't think it is necessary to explain its operation.
If we are interested in converting a Word, the procedure would be the same, but with two Bytes.
And the best way is to see an example in operation, we make the necessary calls to our FC and pass the DWord we want to invert and where we are going to store it. Once online, the simplest way to see it is in Hexadecimal format, as seen in the following images.
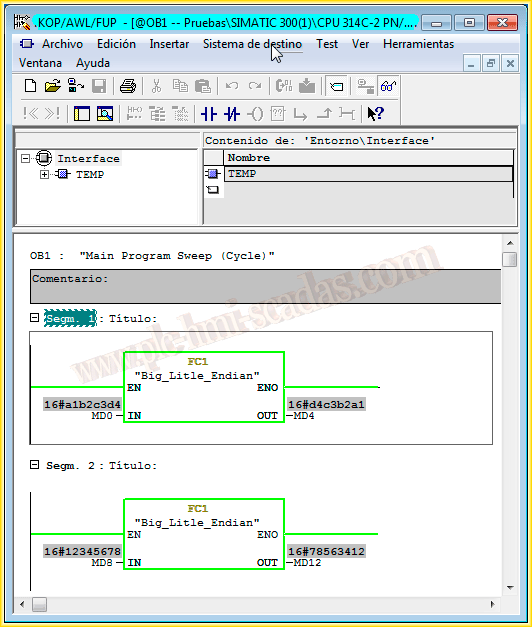
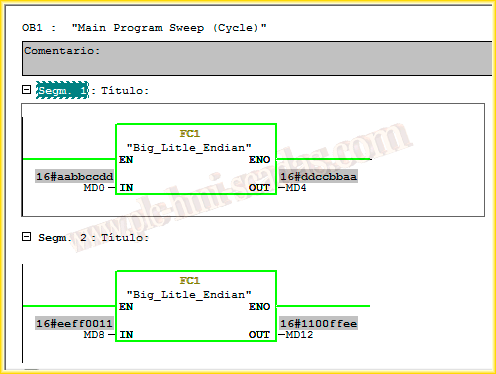
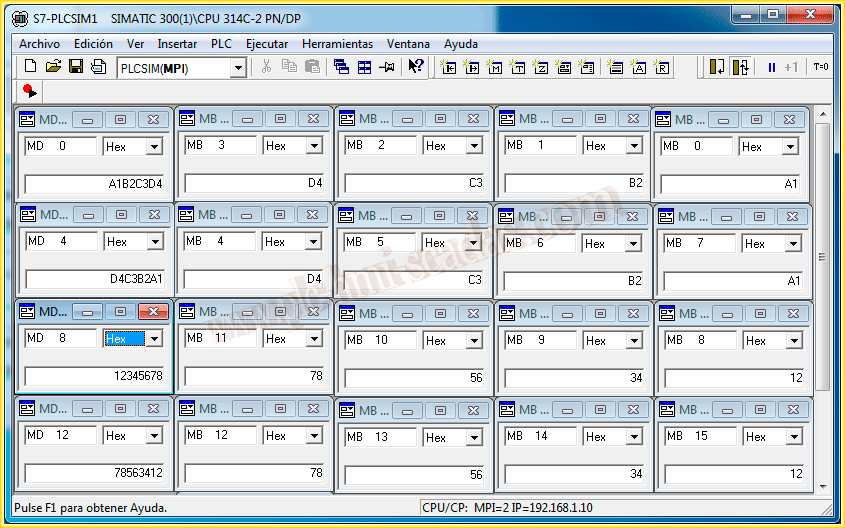
And in the next one, we can observe the value of each Byte and how we transfer it to its opposite address
December 7, 2013